CogX Conference Insights: The Future of AI with StabilityAI and Beyond

Recently, I had the distinct opportunity to attend the CogX Festival at London’s O2 Arena, a premier event focusing on AI and transformational technology. The festival was a vibrant hub of innovative ideas, featuring discussions on the latest advancements in AI with notable figures like Yuval Noah Harari and Jürgen Schmidhuber.
Representing Fynd and PixelBin, I was fortunate to be selected for a 3-day Research Program organized by StabilityAI, which allowed me to attend some of StabilityAI’s exclusive events. Here’s a detailed look into some of the standout sessions and discussions.
The StabilityAI Pavilion

The StabilityAI Pavilion was a visual treat. StabilityAI had created a section in the Magazine London building for their program. Adorned with multiple screens displaying images and videos generated using Stable Diffusion, it also featured iPads that allowed attendees to interact with StabilityAI’s products on their ClipDrop platform. The vibrant setup exuded a futuristic ambiance, setting it apart from the rest of the venue.
State of AI by Tom Mason

StabilityAI’s CTO, Tom Mason, delivered a birds-eye talk on the exponential growth of the Stable Diffusion repository and community. He provided insights into the diverse applications people were developing and the increasing number of apps integrating Stable Diffusion. Mason touched upon its use in various sectors like fashion, movies, and editing. He also delved into other modalities that they are currently exploring, such as language, audio, and video. He shared his insights on how the world will evolve as AI tools advance, with StabilityAI poised to be at the forefront of this innovation.

StabilityAI’s CEO, Emad Mostaque, also came to the pavilion to attend the talk. He provided insights about why he is so committed to open-source and expressed his enthusiasm for the progress of new modalities. Mostaque believes that the evolution from image-based models to audio and video will significantly influence society. He also emphasized the importance of hardware, particularly high-grade GPUs, and shared StabilityAI’s strategy in this domain.
Enhancing Human-Computer Interaction: The Role of Large Language Models in Natural Dialogue Systems

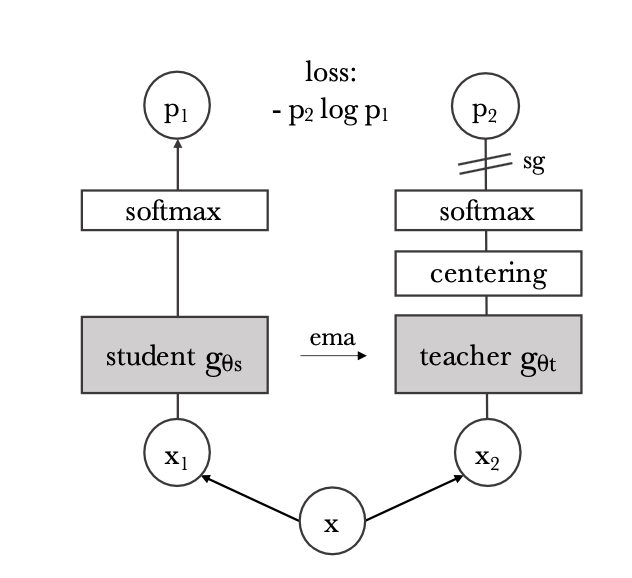
The CarperAI team from StabilityAI, which specializes in large language models (LLMs) like StableLM, spoke about the history of language modeling and where it is headed. They traced the evolution of transformers and discussed the shifts in architecture and training methodologies. The team shared technical details behind the creation of StabilityAI’s open-source StableLM, including aspects like RLHF, Vicuna, LoRA Training, and SwiGLU.
Future of Script Writing with storia.ai
There was a talk by storia.ai CEO Julia Turc on how AI is making a significant impact on scriptwriting. She showcased an upcoming version of their platform that empowers users to craft intricate characters and narratives using their language model. The emphasis was on ensuring consistency and long-range dependency in storytelling and the techniques they employ to achieve this. The talk was very interesting, but personally, I don’t think these platforms will become mainstream until text-to-video becomes significantly better.

StabilityAI Networking Event
At the networking event arranged for the StabilityAI team, research program members, visiting researchers, and entrepreneurs, some of us got into technical discussions about the latest models. This turned out to be quite a productive brainstorming session, with discussions on how Stable Diffusion had evolved from image generation to image editing and some new research techniques recently released.
We also discussed the SDEdit framework and its various applications, especially in the newly released Stable Diffusion XL to enhance image generation.

And on approaches for text-based editing of images, like Prompt2Prompt and InstructPix2Pix.

One major point of discussion was also the addition of vision transformer blocks in SDXL and what role self-attention would play in the context of image and video generation. We all agreed that self-attention would have a much bigger impact on videos where long-range dependencies need to be continually accounted for.

DeepFloyd

There was a talk by researchers from StabilityAI’s DeepFloyd project, Mikhail Konstantinov and Daria Bakshandaeva. They went in-depth on their approach and how their model is different from Stable Diffusion with an emphasis on their use of an LLM to encode the text prompt rather than CLIP. They also explained their approach of gradually increasing the dimension of the latent space in which diffusion occurs for more detailed generations. They showed various examples of how their model is equipped to follow the prompt closely and generate text in images with much higher fidelity.
Many ideas from here were quite relevant to the problems we were facing at Fynd, and after the talk, we had a discussion on Fynd’s products. Coincidentally, they had used some of our products, like Erase.bg and Upscale.media, and had a productive discussion of our roadmap and how we can improve our systems.
Conclusion
I had an amazing time at the conference and got a lot of insights on where AI is headed. I met many people who were passionate about building AI, and that invigorated my sense of passion as well. The talks and discussions were engaging and well-structured, and the people I met were equally interesting. I extend my gratitude to StabilityAI and Fynd for their support and look forward to attending future editions of this conference.