How we rebuilt Fynd’s Infrastructure
On 16th October 2017, as our Infrastructure Team met for a post mortem following the 3rd edition of our flash sale Gone in 60, the mood in the room was quite upbeat. This was in stark contrast to our previous post mortems during which we discussed why and how the platform broke when we got a higher than expected surge in traffic. Both the previous two editions of this sale had resulted in platform wide outages while we scrambled to keep the platform up in the face of rising traffic. This sale brought in a 13x traffic surge compared to a normal weekday and 5x the traffic of our previous flash sales. We had been preparing for this event since some time. We had migrated our core services to their own Auto Scaling Groups, fixed performance bottlenecks on our cart related API endpoints and updated our caching layer configurations to consume less memory. This helped us achieve a consistent response time while the traffic scaled 6x in less than an hour. Here’s a graph showing the traffic ramp up and ramp down around the 7:37 PM mark on one of our busiest services on the day of the sale.

This blog post describes how we rebuilt our infrastructure from scratch to support this scale. Before I describe the actual process, I would be remiss if I didn’t share context on the previous version of our infrastructure.
Infrastructure History
In Fynd’s early days our production infrastructure on AWS was pretty much hacked together. We created EC2 instances using the AWS Management Console, had no reusable AMIs and there was no configuration management tool used to setup and deploy our services. We also made the irreversible mistake of not subnetting our VPC correctly which proved costly as we added more services to the environment. All our EC2 instances were placed in a single subnet which made Security Group management very painful to scale.
As the business started taking off, we grew the size of the engineering team and the complexity of our architecture. But the way our infrastructure was laid out prevented us from scaling seamlessly in line with our growth on the business side. In addition to the outages that I mentioned earlier, the developer experience of building on our platform was not that great either. There were very few engineers who had arcane knowledge of how our production environment was laid out and its gotchas. In the absence of automation, they had to manage their deployments manually following a playbook. This friction took their focus away from building products. We had been improving the infrastructure incrementally, but we needed to give it a deeper overhaul to keep moving quickly in the longer term.
So a few months back we sat down and asked ourselves the question -

Over the course of next few months, we completely re-worked our infrastructure. We retired nearly every single instance and old config, moved our user facing services to run under Auto Scaling, and switched over all services to a new VPC. We spent a lot of time thinking about how we could make a production setup that’s auditable, simple, and easy to use–while still allowing for the flexibility to scale and grow.
Here’s how we did it.
The building blocks of our Infrastructure pipeline are Ansible, Packer, Jenkins and Terraform along with custom tooling to glue these components. Each section below describes how we used these tools to achieve our goals. Here’s a high level overview of the pipeline -

Configuration Management
We chose Ansible as our configuration management tool. It’s written in Python and since a majority of our platform services are written in Python, it became easy for us to peek under the hood of Ansible and debug it. The learning curve is pretty small and we were up and running quickly without requiring any dedicated configuration management setup. Moreover, all our services have a large overlap in their stack so it was easy for us to write reusable Ansible roles for MySQL, MongoDB, Nginx, Redis etc. Today we have 21 Ansible roles out of which 10 are “common” roles that are reused by other roles.
With a uniform structure for these roles, it became very easy to install these roles into different projects to orchestrate a complex stack. Each service which used Ansible for configuration management adhered to a specific list of Ansible tags - bootstrap, deploy which allowed us to use the same ansible playbooks for AMI creation, EC2 instance bootstrapping and orchestrating deploys for each service. We also formed a collection of basic Ansible roles common across all projects which consisted of basic OS packages, monitoring agents, security best practices etc. This formed the foundation of our AMI Build Pipeline driven by Packer and Jenkins.
AMIs with Packer and Jenkins
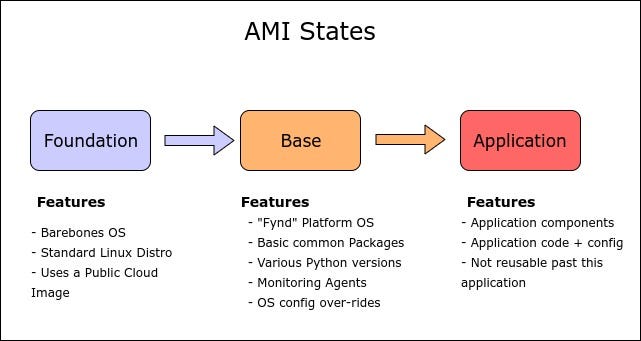
Our Packer AMI Build pipeline takes a stock AMI from AWS AMI Registry and runs the base Ansible role on it to produce a base AMI. Other applications use this base AMI with the Ansible local provisioner to bake their own configuration on top of it. A complex application would contain various server roles in its cluster - app servers, database servers, background workers, cache servers etc. Each of these roles corresponds to an AMI we want to build for that service. We wrote a custom wrapper over Packer which renders Packer JSON templates for each of these server roles. This ensures that we do not hand code Packer templates and can leverage Jenkins to standardize the process of building these AMIs. These AMIs have a specific naming convention which makes the process of querying them trivial within Terraform.
Orchestration with Terraform
While Ansible describes us how to run each service, the actual process of orchestration is managed via Terraform. Terraform gives us a consistent, repeatable, self documenting way of creating and updating our infrastructure. Moreover all the terraform config is managed in a single git repo fynd-infrastructure which gives us an audit log of all the changes that have been carried out in the past. A developer wanting to make changes to the infrastructure checks out a local copy of the repo, makes the required changes, runs terraform plan, terraform apply and pushes his changes upstream. We’ve divided the terraform configuration into a set of modules which can be re-used across various environments.
To give a concrete example, here’s a Terraform module representing our Auto Scaling Groups for Application servers. It automatically fetches the latest application AMI created in the last step and sets up an Auto Scaling group of specified size along with Autoscaling Policies for managing scale up and scale down.
We use the same Terraform module in production as well as pre production environments to setup all our Auto Scaling Groups. The only thing we need to switch out are the IAM keys, and we’re ready to go. Thanks to Terraform, our pre production environment is a near replica of our production environment.
Migrating to our new VPC
Once we had all these pieces in place, we started planning our move to newer auto scaled infrastructure. We first setup a VPC Peering Connection between the legacy production environment and the new one which allowed us replicate database clusters across VPCs and allow newly built services to access all resources in the older VPC via private network routes. We also setup an Application Load Balancer with Auto Scaling groups for all our services behind it. We then slowly started ramping up traffic from our older Nginx boxes to the new ALB and continuously monitored our API endpoints for errors. Once we had confidence that the ALB had warmed up to serve our production traffic we updated DNS records to point to the new ALB. Another advantage of the ALB + Auto Scaling combo is that all our services are now deployed redundantly across AZs which gives us good fault tolerance both at the load balancer and application tier.
With this setup in place we had achieved quite a lot of our goals which we laid out initially. It has also become very easy to get more team members acquainted with deploying auto scaled services on our production environment. We moved 4 additional user facing services to Auto Scaling Groups within the last week and none of the developers working on it had any previous background in Infrastructure.
Follow on Deployments
All our deploy jobs are hosted on Jenkins. Each of these deployment jobs for a service target a specific environment. The services hosted in an Auto Scaling Group are deployed in a rolling fashion to achieve zero downtime during deployments. Since an Auto Scaling environment is ephemeral and the target hosts can change anytime, we use Ansible’s dynamic inventory feature to fetch the public IPs for all hosts in particular Auto Scaling Group before initiating the deploy. Deployments on pre production environments initiate automatically on git push to specific branches whereas deployments on production environments can be triggered with a single click.
What’s next?
We are still a few steps away from completing our infrastructure revamp. We are currently working on migrating our monitoring setup from NewRelic Servers to NewRelic Infrastructure which integrates well with AWS and has a much deeper coverage of host level metrics. We are also building custom tooling to scale out our fleet exactly before a marketing campaign is sent to users. We also have a couple of SPOFs lurking around in our architecture which we intend to remove in order to improve our overall uptime and scalability.
Did you find this post helpful? Let us know in the comments or write to us on devops[at]gofynd.com.

